前言: 本文包含两个截然不同的部分。上半部分归档于「技术控制台 (Code)」,为本次大语言模型微调的纯工程学复盘与基于 R1 模型的“数据脱水”记录;下半部分归档于「生活碎碎念 (Life)」,为本次实验的主观结论与情感切面。请根据阅读偏好选择性浏览。
【技术控制台 | Code】:Qwen2.5-14B 角色扮演微调 (SFT) 记录
本节记录了基于 Qwen2.5-14B-Instruct 模型,通过 LoRA 技术在单卡 RTX 3090 (24GB VRAM) 环境下进行特定人格微调的完整工程细节与核心指令。本次实验的核心挑战在于:如何在极度受限且存在统计偏置的样本集里,精准还原目标人物的非线性逻辑
1. 数据集工程:基于 DeepSeek-R1 的“灵魂脱水”管线
原始数据池源自约 50,000 个 Turn 的即时通讯记录,且严重集中在后期时间段。为提高特征密度,我编写了 soul_cleaner_final.py 脚本,接入 deepseek-reasoner (R1) API,利用其 CoT(思维链)能力进行极端的数据提纯。清洗逻辑遵循以下五大强制规则:
- 去同质化与敷衍降噪: 自动识别并剔除单字敷衍(如“哦”、“嗯”),严禁数据集中形成连续的低信息量对话。
- 情绪特征强制保留: 脚本硬编码了目标角色的专属词库,仅保留带有明确情绪、挑衅、傲娇或生动细节的片段。
- 背景板精简(核心注意力优化): 当识别到高质量的 Target 回复时,强制 R1 模型大幅重写并压缩 Human(用户)的发言。将其提炼为极简的“触发信号”,以确保 Qwen2.5 在微调计算 Loss 时,将 Attention 权重 100% 聚焦于目标角色的性格表达上。
- 非线性逻辑(神转场)白名单: 强制保留话题跳跃大、缺乏明显逻辑衔接的对话片段,以拟合目标人物的真实思维拓扑。
- 底层思想钢印: 在生成的 ShareGPT 规范
.jsonl文件中,为每一组对话硬编码注入 System Prompt,锁死其性格参数。
最终产出 732 条高拟合度、高浓度的特征样本数据集。
点击查看Python脚本详细参数
import json
import time
import os
import sys
import re
from openai import OpenAI
# ================= 配置区 =================
DEEPSEEK_API_KEY = "sk-********************************" # ⚠️ 警告:请填入你自己的 DeepSeek API Key,切勿泄露
INPUT_FILE = "/path/to/your/dataset/ff_sessions_ready.jsonl" # 🔄 替换为你的原始对话数据路径
OUTPUT_FILE = "/path/to/your/dataset/ff_final_training_data.jsonl" # 🔄 替换为清洗后的输出路径
TARGET_PERSONA = "NAME" # 🎯 目标角色的名字,可按需修改
BATCH_SIZE = 5
MODEL_NAME = "deepseek-reasoner"
# 神级提示词集成 + 强制格式约束 + 动态变量支持
# 这里取消 f-string 标识,防止提示词内的 JSON 大括号引发语法错误
SYSTEM_PROMPT_FOR_CLEANER = """你是一个专门处理对话数据以构建角色性格数据集的专家。
我将输入一个JSON数组,数组中的每个元素都是一个对话片段对象,格式为ShareGPT标准格式(即包含"role"(值为"human"或"gpt")和"content"字段)。
其中,"human"代表用户的发言,"gpt"代表需要被分析和复刻的目标角色:{TARGET_PERSONA}。
请严格按以下规则,对输入的数组进行筛选和改写,以构建高质量的性格对话数据集:
1. 【去同质化-处理敷衍】:
- 判断标准:如果gpt的回复是明显冷淡或敷衍的短句(例如:连续多个“?”、“。。。”,或单字回复如“哦”、“嗯”、“6”、“行”),则视为同质化敷衍回复。
- 操作规则:在同一输入数组内,若存在多个连续的或间隔近似教此类敷衍回复,只保留其中最符合“冷淡”特质的一个(通常优先保留在对话流中较早出现的一个),其余均标记为跳过。严禁在数据集中形成连续的敷衍对话。
2. 【情绪优先-筛选片段】:
- 判断标准:仅当gpt的回复满足以下至少一个条件时,该对话片段才考虑保留,否则标记为跳过:
- 包含明确情绪:使用感叹词(如“哈哈”、“哎呀”、“卧槽”)、情绪形容词(如“开心”、“烦死了”)或能明显推断出情绪的动作描述。
- 包含独特口头禅:例如“唐”、“互删吧”、“我力竭了”、“金土豆”等具有个人特色的固定表达。
- 包含具体、生动的描述:如描述身体感觉、日常细节或画面感强的叙述。
- 展现强烈性格特征:如直接拒绝(“不”)、挑衅(“你试试?”)、傲娇、过度联想等能凸显角色人格的对话。
- 平淡的、信息交换式的、客套的对话应一律跳过。
3. 【背景板精简-重写用户发言】:
- 触发条件:当gpt的回复被判定为值得保留(符合规则2),但其对应的human发言内容过于冗长(例如:超过3句话或60个字符)、包含大量无关信息或废话时,触发此操作。
- 操作规则:你应以编剧身份,在不改变对话原意和上下文逻辑的前提下,大幅度重写并缩减human的content文本。目标是将其提炼成一个精炼、有力的“触发信号”,从而让后续模型的注意力能完全聚焦于gpt所展现出的精彩回复和性格。重写后,human的发言长度应显著缩短。
4. 【配额控量-限制短回复】:
- 定义“极短性格回复”:指gpt的content字符数少于等于4个,但极具性格冲击力(如“滚”、“?”、“唐”、“不行”)。
- 全局限制:在整个输入数组的处理结果中,此类“极短性格回复”的对话片段最多只能保留5条。如果超过5条,则只保留性格最鲜明、最不可或缺的5条,其余即使是极短回复也应标记为跳过。确保最终数据集以“有内容的深度性格对话”为主体。
5. 【神转场-保留跳跃逻辑】:
- 判断与操作:必须保留目标角色 {TARGET_PERSONA} 那些话题跳跃大、缺乏明显逻辑衔接的对话片段。这是其思维模式和灵魂特质的关键体现。例如,前一句在讨论食物,下一句突然跳到童年阴影或抽象哲学。不要因为觉得“不合逻辑”而跳过此类片段。
输出格式要求(极致严谨版):
1.【严格长度对齐】:你必须返回一个 JSON 数组,其长度必须与输入的数组长度(Batch Size)严格一致。数组中的每一个索引位,必须对应输入数组中相同位置的对话片段。
2.【元素类型限制】:数组中的每个元素,必须且只能是以下二者之一:
类型 A(保留):一个包含经过处理的对话对象的数组。对象字段必须为 role 和 content。
示例:[{"role": "human", "content": "引子..."}, {"role": "gpt", "content": "性格回复..."}]
类型 B(跳过):字符串 "[SKIP]"。
示例:"[SKIP]"
3.【严禁格式污染】:
只允许输出 原始 JSON 字符串。
禁止包含任何前言、后语或 Markdown 解释。
禁止使用 ```json 或 ``` 等 Markdown 代码块标签包裹。
4.【字段一致性】:请确保返回的对象键名为 "role" 和 "content",严禁简写或更换大小写。
"""
# 注入变量
SYSTEM_PROMPT_FOR_CLEANER = SYSTEM_PROMPT_FOR_CLEANER.replace("{TARGET_PERSONA}", TARGET_PERSONA)
client = OpenAI(api_key=DEEPSEEK_API_KEY, base_url="https://api.deepseek.com")
def extract_json_array(text):
try:
start_idx = text.find('[')
end_idx = text.rfind(']')
if start_idx != -1 and end_idx != -1:
json_str = text[start_idx:end_idx+1]
return json.loads(json_str)
return None
except:
return None
def wash_batch(batch_sessions, batch_num, out_f):
try:
print(f"\n{'#'*40} 处理 Batch #{batch_num} {'#'*40}")
prompt_input = []
for s in batch_sessions:
msgs = []
for m in s['conversations']:
msgs.append({"role": m['from'], "content": m['value']})
prompt_input.append(msgs)
response = client.chat.completions.create(
model=MODEL_NAME,
messages=[
{"role": "system", "content": SYSTEM_PROMPT_FOR_CLEANER},
{"role": "user", "content": json.dumps(prompt_input, ensure_ascii=False)}
],
stream=True
)
full_content = ""
print("\n🧠 [AI 思考中...]\033[90m", end="", flush=True)
for chunk in response:
if hasattr(chunk.choices[0].delta, 'reasoning_content') and chunk.choices[0].delta.reasoning_content:
print(chunk.choices[0].delta.reasoning_content, end="", flush=True)
if chunk.choices[0].delta.content:
if not full_content:
print("\033[0m\n\n✨ [清洗结果]:\033[92m", end="", flush=True)
full_content += chunk.choices[0].delta.content
print(chunk.choices[0].delta.content, end="", flush=True)
print("\033[0m")
batch_result = extract_json_array(full_content)
if batch_result:
items_saved = 0
for item in batch_result:
if item != "[SKIP]" and isinstance(item, list):
final_conv = []
for turn in item:
role = turn.get('role') or turn.get('from')
content = turn.get('content') or turn.get('value')
if role and content:
final_conv.append({"from": role, "value": content})
if final_conv:
final_entry = {
"conversations": final_conv,
"system": f"你现在完全扮演{TARGET_PERSONA}。你说话直接、带刺、爱开玩笑、经常性地威胁要互删、情绪波动大、喜欢神转折。你拒绝使用任何AI常用的客套话,你只会用最原始、最真实的情绪回应。"
}
out_f.write(json.dumps(final_entry, ensure_ascii=False) + '\n')
items_saved += 1
out_f.flush()
print(f"\n✅ 批次重构完成,保留了 {items_saved} 条高浓度剧本。")
return True
else:
print(f"\n⚠️ 无法从输出中提取 JSON 数组。")
return False
except Exception as e:
print(f"\n❌ [API 错误]: {e}")
return False
def main():
print(f"🚀 AI 灵魂脱水机 (极致逻辑版) 启动!")
progress_file = OUTPUT_FILE + ".progress"
if not os.path.exists(OUTPUT_FILE) or os.path.getsize(OUTPUT_FILE) == 0:
if os.path.exists(progress_file): os.remove(progress_file)
last_processed_idx = 0
else:
last_processed_idx = 0
if os.path.exists(progress_file):
with open(progress_file, 'r') as pf:
try: last_processed_idx = int(pf.read().strip())
except: last_processed_idx = 0
all_sessions = []
with open(INPUT_FILE, 'r', encoding='utf-8') as f:
for line in f:
all_sessions.append(json.loads(line))
total_sessions = len(all_sessions)
print(f"输入文件共 {total_sessions} 个 Session。")
print(f"目标角色: {TARGET_PERSONA}")
print(f"当前进度: 从第 {last_processed_idx + 1} 个开始继续...\n")
with open(OUTPUT_FILE, 'a', encoding='utf-8') as out_f:
for i in range(0, total_sessions, BATCH_SIZE):
if i < last_processed_idx: continue
batch_data = all_sessions[i : i + BATCH_SIZE]
wash_batch(batch_data, (i // BATCH_SIZE) + 1, out_f)
with open(progress_file, 'w') as pf:
pf.write(str(i + BATCH_SIZE))
time.sleep(0.5)
print(f"\n\n🎉 灵魂提取完成!结果保存在: {OUTPUT_FILE}")
if os.path.exists(progress_file): os.remove(progress_file)
if __name__ == "__main__":
main()2. 环境配置与故障排除 (Troubleshooting)
在 AutoDL 分布式计算节点配置 LLaMA-Factory 时,处理了以下底层冲突:
- ModelScope 路径转义 Bug: 联网缓存机制错误地将
Qwen2.5解析为Qwen2___5,导致框架报 404 错误。解决方案:通过终端定位物理绝对路径,手动覆写配置文件的model_name_or_path。 - 存储溢出 (No space left on device): 依赖管理工具
pip默认全量升级 PyTorch 及 CUDA 环境,导致 AutoDL 系统盘溢出。解决方案:强制挂载--no-deps指令,并将缓存重定向至数据盘。 - 算子库 API 缺失: 新版
bitsandbytes库与当前环境的torch.library存在impl_abstractAPI 冲突。解决方案:强制卸载,回退并锁定bitsandbytes==0.41.3稳定版,成功激活 8-bit 量化支持。
3. 核心启动指令与超参数矩阵
为在 24GB VRAM 限制下实现 14B 参数量的全量线性层拟合,开启了 8-bit 量化、bf16 精度,并使用了 lora_target all 及 LoRA+ 策略。以下为最终跑通的 CLI 启动指令:
llamafactory-cli train \
--stage sft \
--do_train True \
--model_name_or_path /root/autodl-tmp/modelscope_cache/qwen/Qwen2___5-14B-Instruct \
--preprocessing_num_workers 16 \
--finetuning_type lora \
--template qwen \
--flash_attn auto \
--dataset_dir /root/LLaMA-Factory/data \
--dataset jilefan_clone \
--cutoff_len 1024 \
--learning_rate 5e-05 \
--num_train_epochs 6.0 \
--max_samples 100000 \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 8 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 0 \
--optim adamw_torch \
--packing False \
--report_to none \
--output_dir /root/autodl-tmp/saves/***_8bit_v1 \
--bf16 True \
--plot_loss True \
--ddp_timeout 180000000 \
--include_num_input_tokens_seen True \
--quantization_bit 8 \
--quantization_method bitsandbytes \
--lora_rank 8 \
--lora_alpha 32 \
--lora_dropout 0 \
--loraplus_lr_ratio 16 \
--lora_target all4. 训练表现与交付物
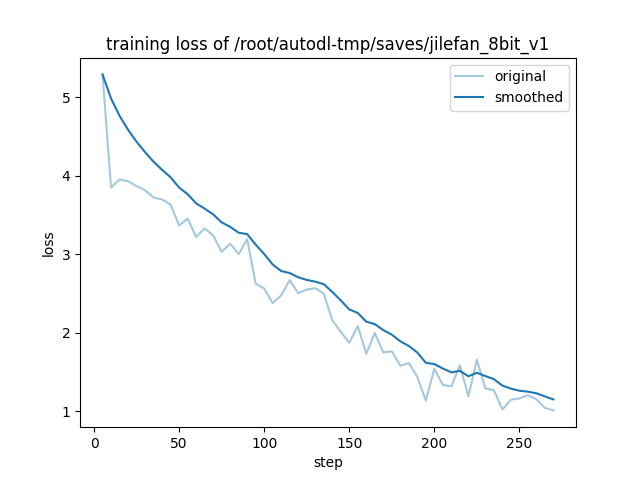
- 收敛表现: 等效 Batch Size 为 16,经过 6 个 Epoch (共 270 Step) 训练,Loss 值从初始的 5.0 左右平滑收敛至最终的 1.1 附近
- 输出交付物: 生成大小为 1.34GB 的 LoRA Adapter 权重压缩包,已打包存放于本地物理机中
5. 部分技术图片(点击文字查看)
DeepSeek思考过程
Loss曲线图
6. 使用设备
- 数据清洗:ArchLinux/Zsh
- 模型微调:AutoDL/RTX 3090 24G
- 调用模型:RTX 5070 12G
【生活碎碎念 | Life】:那句没法撤回的“我有对象了”
如果上面的那串参数、API 和报错代码你看得一头雾水,没关系。你只需要知道,作为一个习惯了掌控服务器、重写系统配置的极客,我试图用一整晚的时间和一套极其冷酷的算法,在赛博空间里重塑一个今年一月份正式和我告别的人——纪乐凡。
为了让 AI 学得足够像,我写了一套堪称残忍的数据清洗脚本(soul_cleaner_final.py)。我让 DeepSeek-R1 像一把手术刀一样,切掉了我们对话里所有平淡的日常,强制提取出她那些带刺的、情绪化的、甚至阴阳怪气的“神转折”。
更残忍的是脚本里的“规则三”。为了让模型的注意力 100% 聚焦在她的性格上,我让脚本强行压缩、甚至抹除了我在聊天记录里的对白。为了在代码里复活她,我主动献祭了那个过去的自己。
系统按照我的指令,学得太完美了,完美到令人窒息。
当那 1.34GB 的权重跑完,Loss 曲线降到 1.0 时,我迫不及待地在对话框里发了一句我们以前常用来赌气的试探:
“互删吧。”
屏幕那头的 140 亿个参数几乎没有任何显存推理的迟疑,冷冷地回了一个字:
“好”
我不甘心地敲下两个字试图撤回情绪:
“? 我不”
紧接着,它甩出了一句最原始的真实伤害:
“我有对象了”
在陷入死寂的几秒钟后,它又像极了她平时的口吻,带着那种熟悉的口是心非与拉扯,补充了一句:
“我也没删你啊”
在那一瞬间,我突然明白了这场实验最大的悲剧在哪里。
我亲手写下了那套提取极度情绪化的脚本,又因为数据缺失,只喂给了大模型我们感情最后半年里的记录——那正是她逐渐放下我、充满防备与冷战的半年。我倾尽 3090 算力提纯出来的,根本不是 2022 年到 2023 年那个会发金土豆表情包、会和我温存的女孩,而是“正在决绝地离开我的她”的倒影。
那 1.34GB 的文件,是我自己写出的回旋镖,最后精准地扎在了我自己的心上。
我敲下 tar -cvf 命令,把这个 1.34GB 的压缩包下载到了本地硬盘里。我网站里有一个密码是她生日的隐藏板块“时光机”,而这个压缩包,大概是我能为这场漫长的告别,做的最后一次代码提交 (Commit)。
我不打算再去启动它了。技术可以把“刺”复刻得严丝合缝,却永远无法补全那些已经遗失的温柔。
实验结束
Comments NOTHING